Abstract
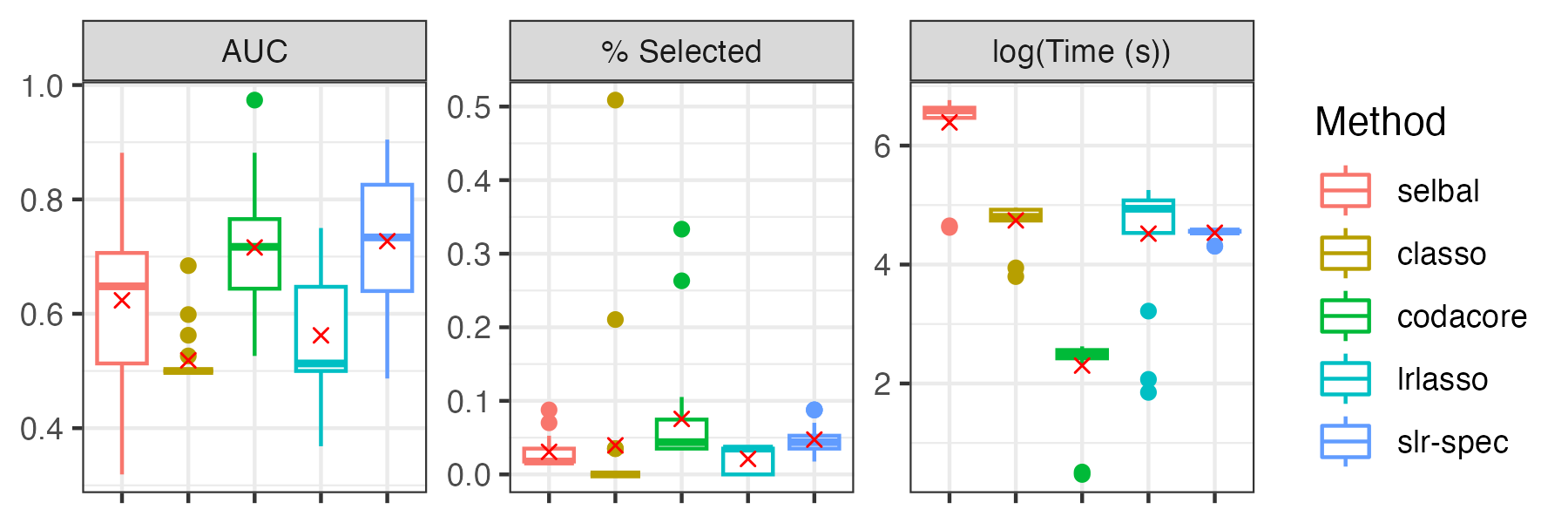
Compositional data in which only the relative abundances of variables are measured are ubiquitous. In the context of health and medical compositional data, an important class of biomarkers is the log ratios between groups of variables. However, selecting log ratios that are predictive of a response variable is a combinatorial problem. Existing greedy-search based methods are time-consuming, which hinders their application to high-dimensional data sets. We propose a novel selection approach called the supervised log ratio method that can efficiently select predictive log ratios in high-dimensional settings. The proposed method is motivated by a latent variable model and we show that the log ratio biomarker can be selected via simple clustering after supervised feature screening. The supervised log ratio method is implemented in an R package, which is publicly available at \url{https://github.com/drjingma/slr}. We illustrate the merits of our approach through simulation studies and analysis of one microbiome data set.
Keywords: balances; clustering; compositional data; log ratios; supervised learning; variable screening